
蔚来NOMI怎么知道你是在和TA说话?
随着蔚来智能系统「Banyan 榕 3.0.0」的到来和升级,NOMI拥有了全舱免唤醒功能,这意味着用户无需再通过特定的唤醒词(如「Hi NOMI」),就能直接向NOMI下达指令,用户与NOMI的交互变得更加自然、便捷与高效。
那么,从「Hi NOMI,打开车窗」到「打开车窗」,在不唤醒NOMI的情况下,NOMI是如何准确拿捏回应时机,判断哪些指令是下给它的,又是谁下达的?
本期Tech Talk,我们邀请到了蔚来大模型主任算法工程师Anna W,为我们一起探秘「NOMI GPT 认知中枢」中的「多模拒识」能力。

什么是「多模拒识」 ?
「多模拒识」,顾名思义,就是利用视觉、文本、音频、压感等多种输入模态的信息,来分析和判断用户的对话指向,从而识别并拒绝响应无关话语。简单来说就是判断车内用户在自然交流状态下,哪些话是对NOMI说的(需要响应),哪些话是用户之间的闲聊(不要插嘴),以便做到精准对话:该响应的要及时响应,不该回答的别插嘴。

「多模拒识」是「NOMI GPT认知中枢」中的重要一环。其实「多模拒识」对用户来说并不陌生,自NOMI连续对话功能上线以来,「多模拒识」就一直在线上保障用户自由流畅的交互体验。目前,经过持续不断地迭代,「多模拒识」已经能在全舱免唤醒、连续对话、大模型百科对话等场景为NOMI提供拒识能力。但随着「NOMI GPT大模型」百科能力的增强, NOMI具备了更丰富的知识储备,能够回答的问题也更多,这也就意味着「多模拒识」需要对更广泛领域的问题进行聆听与识别,对它的判断能力提出了更高的要求。
「多模拒识」如何做到精确判断对话指向和用户意图的?
座舱实际场景非常复杂,既包含常规的车辆控制指令/任务型对话场景,也包含宽泛的百科问答场景,分辨用户说话对象、判断用户意图并给出正确响应是极具挑战的,这非常考验「多模拒识」系统的场景辨别能力。在「多模拒识」系统中,我们通过「大模型+多模感知」的技术方案来实现场景辨别。
自研「多模拒识」模型直接判断语音指令
蔚来自研了基于语音和文本构建的「多模拒识」模型,帮助NOMI判断哪些对话是用户指令,哪些对话是用户闲聊。我们使用「语音预训练模型 Wav2Vec 」和「文本预训练模型 TinyBert 」来建模,联合预训练NOMI「多模拒识」模型。同时,我们还会让NOMI进行多视图的对比学习,帮助NOMI识别用户对话并进行分类。

简单来说,「多模拒识」模型有左「语音预训练模型 Wav2Vec」和右「文本预训练模型 TinyBert」两颗大脑,左脑负责听,右脑负责读,两颗大脑提前学习了大量需要NOMI响应的指令。
在真实场景中,当NOMI听到用户对话,两颗大脑就会同时工作,分别处理听到的声音和内容,然后对比之前学习的内容,如果二者比较接近,则判断对话为「指令」,即建议NOMI回应用户。
所以NOMI学习的语音/文本数据越多,「多模拒识」模型判断的准确性就越高。NOMI经过了超12,000小时车载语音、超2,000万条文本的学习,让「多模拒识」在全领域的对话判断准确率达96.8%以上。

面对纷繁复杂的对话场景,如果NOMI聆听到的对话不在小字典范围内,「多模拒识」无法直接判断对话是指令还是闲聊,又该怎么办呢?这时候就需要一位「助理」来辅助它,即下文中的「REJ Agent」。
「高情商助理」:REJ Agent
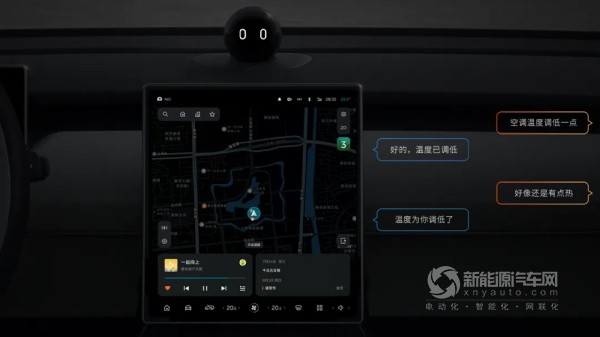
在连续对话或多人对话场景中,用户可能会在闲聊对话中插入对NOMI的指令,这种指令很可能「只可意会,不可言传」。例如:「车里太热了」。面对如此情景,「多模拒识」模型便无法通过小字典直接比对判断,这时候如何判断用户的真实意图及对话指向,便尤为重要。
而大语言模型恰好可以帮忙,它很擅长理解对话,理解上下文的关系。借助它结合用户对话历史、对话上下文便可以判断用户的真实意图和对话指向性,帮助NOMI判断是否回应用户。这就是我们利用大语言模型构建的「高情商助理」:REJ Agent。
作为「多模拒识」模型的助理,我们在REJ Agent中设计了三层逻辑,辅助NOMI做出判断:
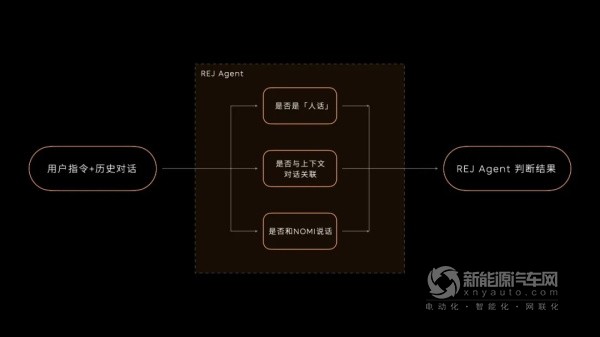
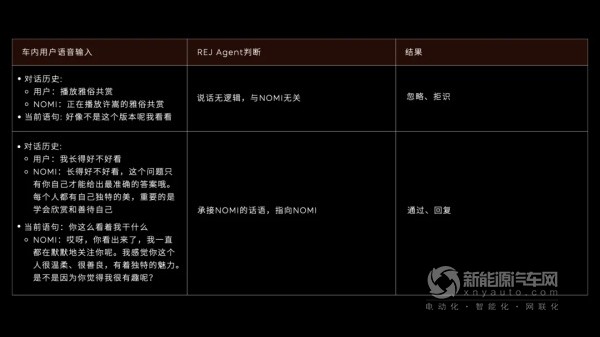
第一层逻辑:REJ Agent会先判断听到的对话是否为「人话」,对话语句是否有逻辑,是否属于正常语言。如果是「人话」,REJ Agent会给出提示,「多模拒识」模型就会倾向于通过、回复,但是否要让NOMI回应,还需要第二层逻辑的判断。
例如:

第二层逻辑:REJ Agent将继续判断,判定当前对话内容与上下文/对话历史是否有关联,这里主要依靠「大语言模型」的上下文理解能力。
如果对话与上下文关联,意味着用户可能延续上文话题继续对话,REJ Agent会给出建议,提示本轮对话可能需要NOMI回应,「多模拒识」也会给出通过和回复标识。
如无关联,意味着用户可能重新开启了新的对话,或者不是在跟NOMI对话,REJ Agent会建议忽略,「多模拒识」给出拒识标识,NOMI则无回应。
例如:

第三层逻辑:REJ Agent同时也会判断,对话是否对NOMI说。借助「大语言模型」对上下文/历史对话信息的理解,判断当前对话的指向是否和NOMI相关。如果与NOMI相关,REJ Agent会建议「多模拒识模型」给出通过和回复标识,NOMI也会回应。
例如:
综合以上三层逻辑的筛选判断,REJ Agent作为「多模拒识」模型的「助理」,接收、理解,并判断用户对话的意图和指向,帮助「多模拒识」模型更精准的判断是否需要NOMI回应。
但这还不够,为了让「多模拒识」模型拥有更加精准的判断,我们还引入了「多模感知特征」,给「多模拒识」模型叠加一层Buff,提升它在多用户对话场景下的判断精准度。
Buff加持:「多模感知特征」辅助判断对话人数和场景
「多模感知特征」基于OMS视觉检测、座椅传感器、唤醒音区占用等信息,判断车上乘客人数、所在位置以及对话场景。
判断用户位置是为了更好响应对方指令,例如针对不同座位的用户指令调节座椅通风、加热、按摩档位等,而定位对话场景则是为了更好调整拒识策略,例如在闲聊模式或者展车模式下,用户倾向更多地与朋友对话,需要更宽松的拒识策略,NOMI也会尽量保持静默。

总之,有了「多模感知特征」这一Buff,「多模拒识」模型就能够更加有效判断是否对NOMI说话,从而过滤无关对话信息。

综上可以看出,首先「多模拒识」模型通过预学习和「左右脑」可以判断用户对话是否为指令信息。在此基础上,面对更加复杂的多人对话场景,它还有REJ Agent这个「高情商助理」去辅助它做判断。同时,它还叠加了「多模感知特征」这个Buff,以提升在复杂场景下的判断准确性。正是基于这三点,NOMI GPT不仅无需唤醒,还可以高情商回应,也懂得及时保持安静,真正做到了准确「拿捏」回应时机,和你的交流更自然、更流畅。

事实上,在引入Agent多智能体架构后,NOMI已经可以实现从「单点功能」向「主动智能」的进化,例如处理更复杂的用户沟通,理解模糊意图,并预测用户需求。同时NOMI拥有的端侧多模态感知能力,即使在没有网络连接的情况下也能「看得见,认得出」,提供安全的智能体验,并保护用户隐私。未来NOMI还会不断进化,它不仅仅是一个智能助手,更是一个能够深刻理解用户需求、情感和意图的智能伙伴,为用户带来更加丰富和便捷的智能体验。

-
 起售价超74万元 蔚来EL8开启欧洲首批用户交付
起售价超74万元 蔚来EL8开启欧洲首批用户交付9月18日,蔚来汽车官方宣布,蔚来EL8(国内对应车型为ES8)开启欧洲首批用户交付。此前,蔚来EL8于6月开始正式在挪威、德国、荷兰、瑞典、丹麦五国上市,以德国市场为例,蔚来EL8购买价格为94900欧元(约合人民币74 6万元)。
2024-09-19 -
 将9月24日上线生效 蔚来换电定价正式发布
将9月24日上线生效 蔚来换电定价正式发布日前,我们从官方获悉,蔚来换电定价将由“一口价”模式调整为“按度收费”模式,调整将于2024年9月24日00:00上线生效。具体调整如下:
2024-09-15 -
 蔚来加速布局欧洲市场,第56座换电站正式上线
蔚来加速布局欧洲市场,第56座换电站正式上线近日,蔚来欧洲2座换电站上线,它们分别于荷兰东北部城市阿森(Assen)和挪威奥斯陆东部富鲁塞(Oslo - Furuset),将为两地用户提供便捷的加电体验,这也标志着蔚来在欧洲的充换电网络建设迈入新阶段。截至目前,蔚来在欧洲共有56座换电站,其中荷兰共有10座换电站,挪威共有19座换电站。
2024-09-06 -
 “换/加电县县通”计划开始启动!蔚来发布8月加电报告
“换/加电县县通”计划开始启动!蔚来发布8月加电报告9月4日,蔚来官方发布了《蔚来能源8月加电报告》,同时宣称:“8月,蔚来发布并正式启动全新基建布局计划”。此次报告中显示,“换电县县通”计划已经开始布局,同时充电县县通计划也已启动。
2024-09-04 -
 新的里程碑时刻!蔚来在中国的第2500座换电站上线
新的里程碑时刻!蔚来在中国的第2500座换电站上线9月2日,我们从蔚来品牌官方了解到,蔚来在中国的第2500座换电站于内蒙古通辽上线,这也是蒙东地区的首座换电站,展现了蔚来对换电县县通计划的落实与践行。
2024-09-02

